XVII CBC 1995 - SBC
COMPACTAÇÃO DE IMAGENS DIGITAIS
Marco Antonio Lemos Perna - M.Sc./IME
Projeto GIS/LAMPADA - FCM/UERJ
Universidade do Estado do Rio de Janeiro
Blv 28 de Setembro 87, fds., 2o andar. Vila Isabel
Rio de Janeiro, RJ, Brasil
e-mail : maperna@uerj.br
RESUMO
É apresentado um estudo de algoritmos de compactação de dados visando a redução de volume de dados para armazenamento de imagens digitais, considerando as características desses tipos de dados para a escolha dos algoritmos que possuam um melhor desempenho para essas imagens.
ABSTRACT
This work presents a study about error-free data compression algorithms, aiming a reduction on volume of digital images, considering the characteristics of these data types to choose the best performance algorithm.
1 - DEFINIÇÃO
Codificar uma fonte (arquivo, origem dos dados) de símbolos (bytes, caracteres, pixels, etc.) significa modificar um sistema de representação da informação do símbolo ou grupos de símbolos emitidos por essa fonte, para outro sistema, de forma que se possa retornar ao sistema original ou próximo dele.
Entre alguns dos objetivos da codificação pode-se citar :
(i) a redução do volume de dados da fonte;
(ii) criptografia;
(iii) como meio auxiliar na transmissão de dados, tanto para correção de erros, quanto para envio de símbolos de controle da transmissão.
A codificação, no escopo desse trabalho, tem como objetivo reduzir o volume de informação necessária para representar uma imagem, gerando códigos para cada símbolo com menos bits, em média, que o símbolo original.
A codificação, neste caso, aplica-se na transmissão de imagens em redes de computadores, em sistemas de teleconferência, em transmissão de documentos por fac-símile, em armazenamento de documentos, em armazenamento de imagens médicas, de satélites, etc.
Os métodos para codificação de imagens baseiam-se na eliminação da redundância das imagens e nas limitações do sistema visual humano. Eles podem ser divididos em:
(i) Métodos Reversíveis: a imagem é codificada e decodificada sem perda de informações. São chamados também de métodos Sem Perda (loss-less, error-free). A codificação é denominada de compactação e a decodificação de descompactação de acordo com recomendação em (BLAHUT, 1990).
(ii) Métodos Irreversíveis: a imagem é codificada e decodificada com perda de informações, porém alcançando taxas maiores. Esse método geralmente envolve três estágios: uma transformação reversível (eliminação de redundância), uma codificação irreversível e uma codificação reversível utilizando algum método reversível. Existem diversos métodos, como por exemplo o JPEG (Joint Photographic Experts Group) (KAY, 1993). A codificação é denominada de compressão e a decodificação de descompressão de acordo com recomendação em (BLAHUT, 1990).
Da Teoria da Informação (ABRAMSOM, 1963) vem que a entropia (quantidade de informação) gerada por uma fonte de símbolos é definida pela Equação 1.
![]()
(1)
onde :
n = número de símbolos a ser codificado;
pi = a probabilidade de ocorrência do i-ésimo símbolo na fonte;
H(S) = entropia da fonte de símbolos. Define um número teórico mínimo de bits por símbolos necessários para codificar mensagens geradas por essa fonte, assumindo que os sucessivos símbolos emitidos da fonte são estatísticamente independentes.
E o número de bits necessários para codificar um símbolo (entropia do símbolo) é dado pela Equação 2.
![]() (2)
(2)
onde:
pi = a probabilidade de ocorrência do símbolo i na fonte;
Hi = define um número teórico mínimo de bits por símbolo, assumindo que os sucessivos símbolos emitidos da fonte são estatísticamente independentes.
Em geral, a compactação de dados é efetuada obtendo símbolos de uma fonte, processando-os, e colocando os códigos em um arquivo (compactado), Figura 1.
Dados da Imagem ---> Pré-processamento ---> Codificação ---> Imagem Compactadada
FIG. 1: Processo de Compactação.
Para o desenvolvimento de um método de compactação de dados que atinja seu objetivo, no caso da utilização de 8 bits para codificar cada símbolo, é preciso que o número médio de bits por símbolo da codificação gerado pela fonte seja inferior a 8 para que o resultado da compactação tenha um tamanho menor que a fonte de símbolos. Na quase totalidade dos casos práticos este número é inferior a 8, e, em geral, não é inteiro. Para se tentar aproximar deste valor mínimo é preciso que se utilize alguma técnica de codificação.
A taxa de compactação (TC), em percentagem, é a relação entre o volume original dos dados a serem compactados e o volume dos dados após a compactação. Ela é definida pela Equação 3.
![]() (3)
(3)
onde :
VO = Volume Original;
VC = Volume Compactado.
Quanto maior a TC (i.e., mais próxima de 100%), menor o volume dos dados compactados.
2 - MÉTODOS DE COMPACTAÇÃO
Grande parte dos métodos de compactação de uso comum hoje em dia recaem em três metodologias:
(i) método Baseado em Dicionário;
(ii) métodos estatísticos;
(iii) métodos simples.
Na prática, o limite entre os métodos não é de fácil distinção, pois alguns métodos não podem ser perfeitamente caracterizados por uma ou outra metodologia, existindo processos híbridos.
Neste trabalho é dado ênfase nos métodos estatísticos, por possuirem maior quantidade de algoritmos baseados neles. Além de que, seus conceitos podem ser utilizados em outros métodos ou em métodos híbridos. São também apresentados um método simples e um baseado em dicionário.
3- MÉTODOS ESTATÍSTICOS
A necessidade de se predizer corretamente a probabilidade de ocorrência dos símbolos (e.g., níveis de cinza, ou valores dos pixels) obtidos da fonte é inerente da natureza dos métodos estatísticos.
O princípio desse tipo de codificação é reduzir o número de bits necessários para codificar um símbolo a medida que sua probabilidade de ocorrência aumenta (primeira condição para compactação).
Por exemplo: em uma imagem com pixel de 8 bits, o nível de cinza 35 representa 25%, ou seja, possui uma probabilidade de 1/4 dos pixels de entrada, ele será codificado com apenas 2 bits, pois sendo H = log2 (1/(1/4)), H = 2. Se o nível 56 possui uma probabilidade de 1/1024 que é aproximadamente 0,1% dos pixels de entrada, ele será codificado com 10 bits, pois, sendo H = log2 (1/(1/1024)), H = 10. Se o modelo não estiver gerando probabilidades corretamente, ele poderá trocar as probabilidades e usar 10 bits para representar o 35 e 2 bits para representar o 56, causando expansão da imagem ao invés de compactação, já que 25% da imagem aumentará de tamanho em 2 bits por pixel original e apenas 0,1% da imagem sofrerá redução de 6 bits por pixel original.
A segunda condição para compactação estabelece que o modelo probabilístico deva fazer predições que divirjam de uma distribuição uniforme. Tanto melhor o modelo faça essas predições, melhor será a taxa de compactação. Por exemplo, um modelo poderia ser criado para atribuir a todos os 256 níveis de cinza, de uma imagem com pixel de 8 bits, uma probabilidade uniforme de 1/256, ou seja, uma distribuição uniforme. Esse modelo cria um arquivo de saída que é exatamente do mesmo tamanho do arquivo origem, porque cada nível de cinza é codificado com sua entropia exatamente igual a 8 bits.
Somente encontrando corretamente probabilidades que divirjam de uma distribuição uniforme o número de bits pode ser reduzido, levando à compactação. O aumento das probabilidades tem que refletir corretamente a realidade, como prescrito na primeira condição.
A probabilidade de ocorrência de um dado símbolo emitido pela fonte não é fixo. Dependendo do modelo probabilístico utilizado, a probabilidade de ocorrência de um símbolo pode mudar totalmente.
Por exemplo: quando compacta-se um texto, como o penúltimo parágrafo, a probabilidade de um caracter de controle para finalização de parágrafo no texto é 1/280, ou seja uma ocorrência (no final do parágrafo) em 280 caracteres (incluindo espaços). Essa probabilidade é determinada para todo o texto, dividindo o número de ocorrências do caracter pelo número total de caracteres. Mas utilizando-se de uma técnica de modelagem que visualize o caracter anterior, a probabilidade mudará. Nesse caso, se o caracter anterior for um ".", a probabilidade de ocorrência de um caracter de controle para finalização de parágrafo passa para 1/2, pois só existem dois caracteres '.' e é apenas após o último '.' que termina o parágrafo.
Essa técnica melhorada de modelagem leva a uma melhor taxa de compactação, mesmo que ambos os modelos estejam gerando corretamente as probabilidades.
3.1 - MODELAGEM DE CONTEXTO-FINITO
O tipo de modelagem denominada modelagem de "contexto-finito", (NELSON, 1991) baseia-se em uma idéia bem simples : A probabilidade de cada símbolo é calculada em relação ao contexto no qual aparece. Nos exemplos já mostrados, o contexto consiste nos símbolos emitidos anteriormente pela fonte que são visualizados para o cálculo da probabilidade de ocorrência, o que é chamado ordem do modelo. O termo "finito" é empregado por levar em consideração um número finito de símbolos anteriores ao símbolo corrente.
O modelo mais simples de contexto-finito é o modelo ordem-0, no qual a probabilidade de cada símbolo independe de qualquer símbolo anterior. Para implementar esse modelo, necessita-se somente de uma tabela simples contendo a freqüência que cada símbolo possue na fonte, no caso de uma imagem, o seu histograma. Para um modelo ordem-1, serão geradas 256 diferentes tabelas de freqüências, porque será necessário guardar em separado o conjunto de freqüências para cada possível contexto. Da mesma forma, um modelo ordem-2 necessita gerenciar 65536 diferentes tabelas de contextos. Modelos com ordem acima de zero são chamados de modelos de Markov (ABRAMSOM, 1963) (Markov Information Source).
A Figura 2 representa o modelo ordem 1. A tabela da esquerda representa o símbolo corrente, sendo que está se considerando símbolos com 8 bits e conseqüentemente 256 valores diferentes. Cada índice corresponde a um símbolo e armazena sua freqüência. As tabelas apontadas por cada símbolo representam o símbolo anterior ao corrente e suas freqüências são dependentes do símbolo corrente.
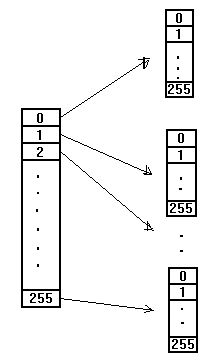
FIG. 2 : Tabelas de freqüência do modelo ordem 1.
3.2 - MODELO ADAPTÁVEL
De acordo com o aumento da ordem do modelo, a taxa de compactação melhora, caso haja uma grande quantidade de símbolos estatísticamente dependentes, pois são necessários menos bits para a codificação. Por exemplo: a probabilidade do caracter "u" aparecer num texto pode ser de cinco por cento, mas se o caracter anterior do contexto for o "q", a probabilidade pode subir para noventa e cinco por cento. Ser capaz de predizer caracteres com alta probabilidade diminui o número de bits necessários, e grandes contextos permitem efetuar predições melhores.
Infelizmente, ao mesmo tempo que a ordem do modelo aumenta linearmente, a memória por ele consumida aumenta exponencialmente. Com um modelo ordem-0, o espaço consumido pelas estatísticas pode ser tão pequeno quanto 256 bytes. Mas, uma vez que a ordem do modelo passe para 1 ou 2, mesmo o modelo melhor idealizado e implementado consumirá milhares de bytes.
Uma forma genérica de compactação de dados é desenvolvida em dois passos:
(i) ler os dados e gerar as estatísticas para o modelo
(ii) codificar os dados, compactando-os.
Os métodos que utilizam este processo são conhecidos como estáticos. Pois, as estatísticas das probabilidades de ocorrência são armazenadas junto com os dados compactados para posterior descompactação, ou seja, as estatísticas são fixas ou estáticas. Isso acarreta problemas se as estatísticas do modelo consumirem mais espaço do que os dados a serem compactados.
A solução para o problema é a utilização de uma compactação adaptável (ou adaptativa em um passo, ou dinâmica), na qual ambos, o compactador e o descompactador, começam com o mesmo modelo e a compactação ou descompactação é efetuada em apenas um passo, ajustando o modelo probabilístico automaticamente à medida que recebe os símbolos da fonte.
O compactador codifica um símbolo utilizando um modelo existente (default), atualizando-o para responder pelo novo símbolo. O descompactador, da mesma forma, decodifica o símbolo utilizando o modelo existente, atualizando-o em seguida. Como o algoritmo para atualizar o modelo funciona de forma idêntica para o compactador e para o descompactador, o processo pode perfeitamente ser efetuado sem a passagem da tabela de estatísticas do compactador para o descompactador. A atualização do modelo é o ponto fraco do algoritmo onde a compactação adaptável perde desempenho.
Para o modelo ordem-0, os mesmos símbolos podem estar armazenados em uma disposição (forma) diferente, pode-se até misturá-los aleatoriamente que a taxa de compactação permanecerá a mesma, pois a probabilidade de ocorrência de cada símbolo não é alterada. Mas para modelos de ordem diferente de zero, a disposição de armazenamento modifica as estatísticas, pois o contexto é alterado.
Atualmente, a maioria dos métodos de compactação utilizados em imagens são de uso geral, ou seja, não foram desenvolvidos para esse tipo específico de dado. Exemplo disso são os formatos GIF (Graphics Interchange Format) e PCX, entre outros, que implementam os métodos LZW (Lempel, Ziv e Welch) e RLE (Run Length Encoding) respectivamente.
4 - ALGORITMOS
4.1 - RUN LENGTH ENCODING
O Run Length Encoding (RLE) é um método de compactação simples que codifica símbolos repetidos dispostos em seqüência. Uma seqüência é uma série de símbolos iguais, que são trocados no arquivo compactado por um código com o número de redundâncias seguido do símbolo original. Para imagens, em geral esse algoritmo não é eficaz, havendo a necessidade de modificar o algoritmo básico para que compense a sua utilização. Porém, para imagens de mapas digitalizados é um bom método, uma vez que o número de cores ou níveis de cinza necessários a quantizar na imagem é relativamente pequeno, ocasionando seqüências de redundância relativamente grandes. Algumas variações do algoritmo, para imagens, foram estudadas por Almeida (ALMEIDA, 1989).
Uma das variações mais utilizadas atualmente é o formato PCX (KAY, 1993), concebido para o PaintBrush da ZSoft, utilizado em microcomputadores da linha IBM-PC. É um formato de implementação simples, com um cabeçalho com informações sobre a imagem.
4.2 - CODIFICAÇÃO DE HUFFMAN
É um método estatístico, que associa códigos de tamanho fixo a símbolos, cujo algoritmo clássico (HUFFMAN, 1951) pode ser exemplificado da seguinte forma:
Suponha que a fonte a ser codificada é "ACATACA", com quatro "A", dois "C" e um "T". Essa situação é representada como se segue:
4 2 1
| | |
A C T
Combina-se os dois menos freqüentes símbolos em um, resultando na nova freqüência 2 + 1 = 3:
4 3
| / \
A C T
Repete-se o passo acima até que todos os símbolos estejam combinados em uma árvore:
7
/ \
/ 3
/ / \
A C T
Inicia-se no topo (raiz) dessa árvore de codificação, e navega-se para o símbolo que se deseje codificar. Se for para a esquerda, envie um bit '0'; de outra forma envie um bit '1'. Assim, "A" é codificado por '0', "C" por '10', "T" por '11'. Logo, "ACATACA" será codificado em dez bits, '0100110100'.
Para decodificar é necessário conhecer a árvore de codificação (estatísticas) original, que deverá estar no arquivo compactado. Esse método é denominado de Huffman estático, utilizado pelos utilitários pack e unpack do UNIX System V da AT&T.
Uma modificação desse algoritmo clássico é o modelo adaptável, proposto por (FALLER, 1973). Independentemente, (GALLAGER, 1978) também propôs o mesmo método, e o algoritmo proposto por ambos foi melhorado por (KNUTH, 1985). Assim o algoritmo que implementa o Huffman adaptável ou dinâmico é conhecido por algoritmo FGK (Faller, Gallager, Knuth).
4.3 - CÓDIGO ARITMÉTICO
É um método estatístico, cuja concepção original foi proposta por (ELIAS, 1963). As primeiras implementações práticas datam de 1976 (RISSANEM, 1976) e (PASCO, 1976). Uma implementação em linguagem C é descrita por (WITTEN, 1987). É um método patenteado pela IBM.
A codificação de Huffman codifica um símbolo com sua entropia aproximada para um número inteiro de bits. A codificação aritmética tem desempenho melhor em taxa de compactação por essa restrição não existir.
A codificação aritmética não utiliza a metodologia de codificar um símbolo em um código específico, transformando a seqüência completa de símbolos da fonte em um único número real. Isso só é possível em computadores através de artifícios de programação, pois, a aritmética de computador utiliza um número finito e pequeno de bits para implementar os tipos de dados.
O processamento da codificação aritmética resulta em um número menor que 1 e maior ou igual a 0, que pode ser decodificado para a seqüência de símbolos original.
Para gerar esse número, são atribuídos aos símbolos um conjunto de probabilidades. A seqüência "MARCOPERNA", por exemplo, tem uma distribuição de probabilidade mostrada na Tabela 1. A cada símbolo é, então, atribuída uma subdivisão da faixa de valores entre 0 e 1, correspondendo, em tamanho, a sua probabilidade de ocorrência, como mostra a Tabela 1.
TABELA 1 : Probabilidade e faixa dos símbolos.
|
Sím-bolo |
Probabi-lidade |
Faixa
|
|
A C E M N O P R |
2/10 1/10 1/10 1/10 1/10 1/10 1/10 2/10 |
0.0 <= f < 0.2 0.2 <= f < 0.3 0.3 <= f < 0.4 0.4 <= f < 0.5 0.5 <= f < 0.6 0.6 <= f < 0.7 0.7 <= f < 0.8 0.8 <= f < 1.0 |
Com a tabela de freqüências pronta inicia-se a codificação construindo duas tabelas, que possuem o número gerado pelo menor valor e pelo maior valor respectivamente. O primeiro símbolo, a letra "M" está contida na faixa 0.4 <= f < 0.5, o valor mínimo e o máximo são colocados nas tabelas de menor e maior valor respectivamente, como mostra a Tabela 2. A tabela é finalizada de acordo com o seguinte algoritmo :
menor = 0.0;
maior = 1.0;
enquanto não terminar a seqüência de símbolos faça
{
faixa = maior - menor;
maior = menor + faixa * maior_da_faixa(símbolo);
menor = menor + faixa * menor_da_faixa(símbolo);
}
TABELA 2: Codificação Aritmética.
|
Sím-bolo |
Menor valor |
Maior valor |
|
M A R C O P E R N A |
0.0 0.4 0.40 0.496 0.5008 0.50224 0.502408 0.5024152 0.50241712 0.502417360 0.5024173600 |
1.0 0.5 0.42 0.520 0.5032 0.50248 0.502432 0.5024176 0.50241760 0.502417408 0.5024173690 |
Onde "maior_da_faixa(símbolo)" é uma função que retorna o maior valor da faixa do símbolo, passado como parâmetro, de acordo com a Tabela 3.1, e "menor_valor_faixa(símbolo)" retorna o menor valor. A cada iteração da estrututa "enquanto", os valores calculados de maior e menor são colocados na Tabela 3.2, em seus símbolos correspondentes.
O menor valor calculado para o último símbolo é a codificação final da seqüência, ou seja, 0.5024173600.
Uma prova matemática formal de que o processo converge para o limite da entropia é dada por (PASCO, 1976).
Uma implementação em linguagem C é descrita por (NELSON, 1991), utilizando modelos de Markov superiores a zero, o que torna esse método bastante apreciável, considerando que memória e velocidade não são problemas.
4.4 - CODIFICAÇÃO LZW
Esse algoritmo foi proposto por Lempel e Ziv, em 1977; melhorado em 1978 (LEMPEL, 1978); e modificado por (WELCH, 1984) pesquisador da Sperry, cuja fusão com a Burroughs gerou a UNISYS. É um método adaptativo de um passo que associa seqüências de tamanho variável de símbolos a códigos de tamanho fixo ou variável. Essas características levam o método ser chamado de Método Baseado em Dicionário.
É também um método dependente do contexto da ocorrência do símbolo na fonte. É patenteado pela UNISYS, tendo a IBM também patenteado sua versão.
O algoritmo consiste em preparar uma tabela que pode conter milhares de itens. Inicialmente coloca-se da posição zero até a posição 255 os usuais 256 caracteres. Lê-se vários símbolos da fonte, e pesquisa-se na tabela pela mais longa correspondência. Supondo que a mais longa correspondência é dada pela seqüência "ABC". Coloca-se a posição de "ABC" na tabela. Le-se o próximo símbolo da fonte. Se ele for "D", então coloca-se uma nova seqüência "ABCD" na tabela, e reinicia-se o processo com o símbolo "D". Se houver overflow da tabela, descarta-se o mais antigo ítem ou, preferencialmente, o menos usado.
As variações básicas de implementação consistem em usar códigos de tamanho fixo (LZW estático) ou variável (LZW dinâmico). O conceito de estático e dinâmico aqui é diferente do conceito dos métodos estatísticos. Os códigos de tamanho fixo geralmente não fornecem um bom desempenho comparados com os de tamanho variável. Normalmente começa-se a codificação com códigos de 9 bits e a medida que o algoritmo necessita de mais bits, aumenta-se o código em um bit, passando para 10 bits e assim sucessivamente.
O formato GIF (Graphics Interchange Format) (COMPUSERVE, 1989), da CompuServe, usa esse método com uma variação de 3 a 12 bits para o tamanho do código. Outra melhoria ao método é a limpeza da tabela de itens sempre que necessário, reiniciando-se a tabela como estava no início da codificação. Uma implementação em linguagem C foi descrita por (NELSON, 1989) e melhorada por (REGAN, 1990).
5 - CONCLUSÕES
Foram realizados testes com implementações dos algoritmos descritos, com os formatos GIF e PCX e também com o programa PKZIP. Foi utilizada para teste a banda 2 de uma imagem LANDSAT TM da cidade do Rio de Janeiro, denominada RJ2, que possui o histograma da Figura 3.
O histograma mostra uma grande concentração no início do eixo de valores de niveis de cinza o que indica que a imagem não tem uma distribuição uniforme, permitindo o uso de métodos estatísticos de ordem-0.
Como a imagem não possui seqüencias longas de pixels verifica-se através da Figura 4 que o método RLE e o formato PCX não tem, como esperado, um bom desempenho. Os métodos de Huffman (HUF) e aritmético ordem-0 (ARIT0) tiveram desempenho semelhante, com o ARIT0 um pouco melhor, e o Huffman dinâmico (AHUF) se colocando no mesmo nível. O LZW venceu no que diz respeito a relação velocidade de compactação e taxa de compactação, perdendo apenas para o PKZIP de algoritmo proprietário, e para os métodos aritméticos de ordem 1, 2 e 3 (apenas em taxa de compactação), que são extremamente lentos.
Em relação aos métodos aritméticos, verificou-se que o de ordem 1 é excelente para imagens, apesar de lento. E que quanto maior for a ordem, pior é seu desempenho em taxa de compactação, devido ao fato de que uma imagem de satélite não possui um contexto muito maior que o pixel anterior, fato que se inverte em arquivos texto.
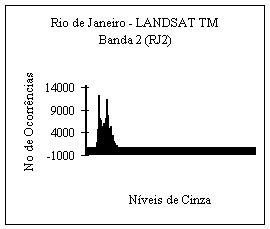
FIG. 3 : Histograma da imagem RJ2
Sob o ponto de vista de armazenamento permanente com pequena recuperação de imagens o código aritmético ordem 1 é o mais indicado, pois obteve a melhor taxa de compactação. Caso se queira recuperar mais frequentemente as imagens e a velocidade se torne fundamental, existem três opções: a primeira é utilizar o LZW cujo algoritmo pode ser manipulado pelos desenvolvedores permitindo alteração do código; a segunda é utilizar o formato GIF que implementa o LZW, porém de forma não muito otimizada, que têm o benefício de ser um formato padrão que diversos softwares gráficos utilizam; a terceira é utilizar o PKZIP que fornece o fonte do algoritmo de descompactação, é o mais rápido compactador e possui uma taxa de compactação melhor que o LZW, porém o algoritmo de compactação não é fornecido.
Resta outra opção só indicada caso se queira utilizar um formato padrão, que seja lido em diversos softwares, e apesar de não possuir uma taxa de compactação boa, é rápido e o algoritmo é extremamente simples de implementar. É uma forma fácil inclusive de testar programas que manipulem imagens, deixando que o desenvolvedor só precise acoplar um algoritmo melhor quando o programa já estiver pronto.
O desenvolvedor do programa pode também transferir a imagem compactada para a memória RAM e só a partir daí descompactá-la para o vídeo. Esse artifício é interessante no caso da imagem ser exibida no vídeo diversas vezes e para isso ter que acessar o disco rígido, que é mais lento que a RAM. Caso se queira fazer acesso aleatório aos pixels da imagem, pode-se compactar por linha e manter um índice de início de cada linha da imagem, descompactando-se só a linha que interessar. Caso esse acesso ao pixel permita alteração do mesmo, se faz necessário a utilização de uma estrutura de lista (ou outra estrutura) dos índices de início de linha, pois o comprimento compactado da linha alterada pode ser diferente do original e a linha não poderá mais estar na mesma posição de memória, a lista permitirá que não se perca a seqüencialidade da imagem.
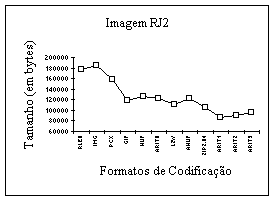
FIG. 4 : Desempenho dos compactadores
6 - REFERÊNCIAS BIBLIOGRÁFICAS
ABRAMSOM, Norman. Information Theory and Coding. McGraw-Hill Eletronic Science Series, 1963.
ALMEIDA, Marcos de. Alternativas para Armazenamento de Imagens Discretas, tese de mestrado IME, Janeiro de 1989.
APIKI, S. Lossless Data Compression. Byte, Março 1991.
BELL, T.C. IEEE Transactions COM-34: 1176-1182, 1986.
BELL, Timothy C.; CLEARY, J.G.; WITTEN, I.H. Text Compression. Englewood Cliffs, N.J.: Prentice Hall, 1990.
BLAHUT, Richard. Principles Practices For Information Theory. Addison-Wesley Publishing Company, 1990.
BUTRON, Cesar A. Gonzales. Advances in Image Compression Techiniques. IBM Research Division. T.J.Watson Research Center. Yorktown Heights, NY 10598.
CASE, Shaun. Run Length Encoding compressor program, atman%ecst.csuchico.edu@RELAY.CS.NET, (internet), 1991.
CHUI, Paul. A C++ PCX File Viewer for Windows 3. Dr.Dobb's Journal, Julho 1991.
COMPUSERVE INCORPORATED. GIF - Graphics Interchange Format. 1989.
ELIAS, P. Information Theory and Coding. N.Abramson, McGraw-Hill Book Co., Inc, New York, 1963.
FALLER, Newton & SALENBAUCH, Pedro. Compressão de Dados no Unix. Boletim do Plurix nş 15, NCE-UFRJ, 1991.
FALLER, Newton. An Adaptative System for Data Compression. Records of Seventh Asilomar Conference on Circuits, Systems and Computers, Pacific Grove, CA, E.U.A., 593-597, 1973
FALLER, Newton. Sistema adaptativo para compressão de dados, Tese de Mestrado, COPPE-UFRJ, 1973.
GALLAGER, R.G. Variations on a Theme by Huffman. IEEE Transactions on Information Theory IT-24(6): 668-674, Nov.1978.
GONZALEZ, Rafael C.. Digital Image Processing. 2Ş edição, Addison-Wesley Publishing Company, 1977.
GRAEF, Gerald L. GRAPHICS FORMATS, A close look at GIF, TIFF and other attempts at a universal image format. Byte, Setembro 1989.
HELD, G. Compressão de Dados. Editora Érica, 1992.
HUFFMAN, David A.. A Method for the Construction of Minimum-Redundancy Codes. I.R.E.. 6 de dezembro de 1951.
JAIN, Anil K. Fundamentals of Digital Image Processing. Prentice Hall Information and System Sciences Series.
KATZ, Phil. PKZIP.EXE 2.04 & PKARC.EXE 3.6. PKWare(Glendale, Wisc., USA).
KAY, David C. & LEVINE, John R.. Graphics File Formats. Windcrest/McGraw-Hill, 1993.
KNUTH, D.E. Dynamic Huffman Coding. Journal of Algorithms 6: 163-180, 1985
LEMPEL, A. & ZIV, J.. A Compression of Individual Sequences via Variable-Rate Coding. IEEE Transactions on Information Theory IT-24(5), Setembro 1978.
LEMPEL, A. & ZIV, J.. A Universal Algorithm for Sequencial Data Compression. IEEE Transactions on Information Theory IT-23(3), Maio 1977.
MEADOW, Anthony; OFFNER, Rocky; BUDIANSKY, Michael. Handling Image Files with TIFF. Dr.Dobb's Journal, Maio 1988.
NELSON, Mark R.. Arithmetic Coding and Statistical Modeling. Dr.Dobb's Journal, Fevereiro 1991.
NELSON, Mark R.. LZW Data Compression. Dr.Dobb's Journal, Outubro 1989.
OKUMURA, Haruhiko. Data Compression Algorithms of LARC and LHarc, COMPRESS.TXT, Science SIG (forum) of PC-VAN Japan.
PERNA, Marco A. L.. Módulo de Compactação de Imagens Discretas, tese de mestrado IME, fevereiro de 1994.
PRATT, William K. Digital Image Processing. Wiley-Interscience, 1978.
QUINTANILHA, José Alberto. Processamento de Imagens Digitais. Simpósio Brasileiro de Geoprocessamento. Anais EPUSP, São Paulo - SP, P-37-52, Maio 1991.
QUIRK, Kent. Translating PCX Files. Dr.Dobb's Journal, Agosto 1989.
REGAN, Shawn M.. LZW Revisited. Dr.Dobb's Journal, Junho 1990.
SEDGEWICK, R. Algorithms, 2Ş edição Addison-Wesley, 1988.
STORER, J.A. & SZYMANSKY, T.G. LZSS. J. ACM, 29: 928-951, 1982.
STORER, J.A. Data Compression Methods and Theory. Computer Science Press, 1988.
THOMAS, Kas. ENTROPY The Key to Data Compression. Dr.Dobb's Journal, Fevereiro 1991.
VITTER, J.S. Design and Analysis of Dynamic Huffman Codes. Journal of the Association for Computing Machinary, Outubro 1987.
WELCH, Terry. A Technique for High-Performance Data Compression. Computer, IEEE, 17(6), Junho 1984.
WITTEN, Ian H. et alli. Arithmetic Coding for Data Compression. Communications of the ACM, Junho 1987.